Week 1: Introduction to OLS Regression
🎓 Welcome to Week 1
Course: Statistics and Data Science II
Focus: Associations, regression, interpretation, and model intuition
🔍 Associations
- 🤔 Today we’ll start with associations. What does it mean?
- 🧠 Much of social science begins with a hypothesis about associations in the world:
- Between 🎓 education and 💰 income, 📱 screen time and 😊 well-being, ⚧ gender and 💭 attitudes, or ⏱️ study time and 🧾 exam performance.
- ❤️ To make the content of this course meaningful, you need to connect it to your own interests.
- What associations interest you? Take 1 minute to think ⏰.
✏️ Drawing Exercise
I want you to think about the association between hours studied and exam results for SDS-I.
- 📝 Task: On paper, sketch a scatterplot (points) of how you think these would be associated for you.
- The x-axis is the number of hours you studied for the SDS-I exam,
- The y-axis is your percentage of correct answers on the exam.
Associations
![]()
💬 Discussion
- How would you describe your sketched association?
- If you would connect your points, what is the shape of the line?
What Are We Really Asking?
- Would I have done better if I had studied more?
- Would someone else have done worse if they had studied less?
- Does studying cause better performance?
The Problem of the Missing Reality
We can imagine two possibilities for each student:
\[
Y_i(1) = \text{Exam score if student } i \text{ studies more}
\] \[
Y_i(0) = \text{Exam score if student } i \text{ studies less}
\]
These are called potential outcomes.
The Fundamental Problem of Causal Inference
For each student, we only observe one outcome:
- We see what happened, not what could have happened
- This missing data problem is what makes causality hard
- We cannot observe both \(Y_i(1)\) and \(Y_i(0)\).
So What Can We Do?
We can collect observed data:
- How many hours each student studied
- Their actual exam results
- From this we can look for patterns across individuals
→ This is the domain of statistical modeling
You Already Made a Hypothesis
Earlier you imagined your own points of potential outcomes on a scatterplot.
Put together, these plots form a collective hypothesis about the relationship between:
- Study time
- Exam performance
- The next task would be to test it with data.
What is Regression?
Regression is a way to model the relationship between variables.
- Predict an outcome (
Y), often called the dependent variable.
- Use one or more predictors (
X), often called our indepedent variable(s)
- We can use it to make predictions 🎯
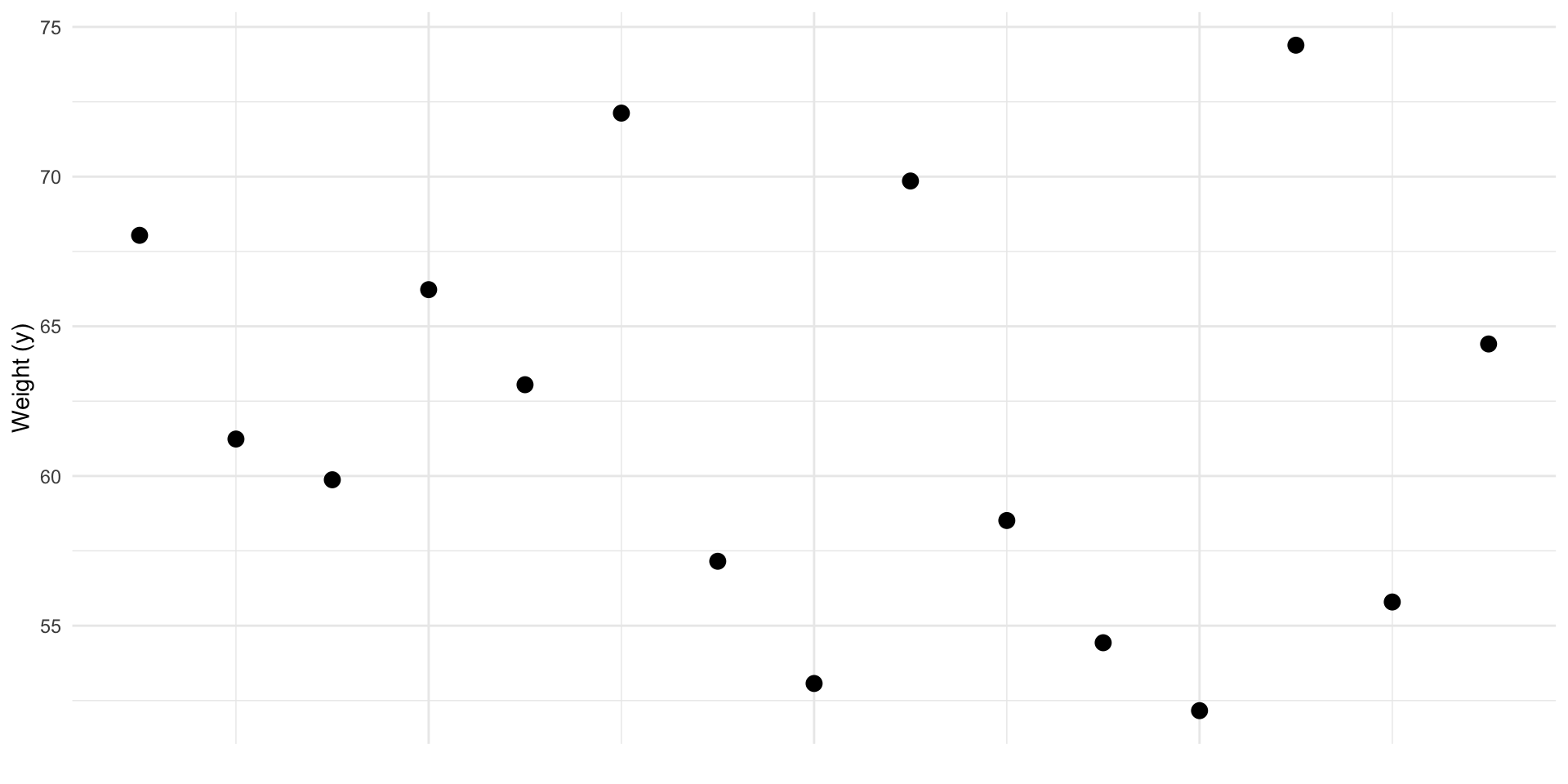
Predict y
Given this data. What’s our best prediction of a new \(y_i\)?
![]()
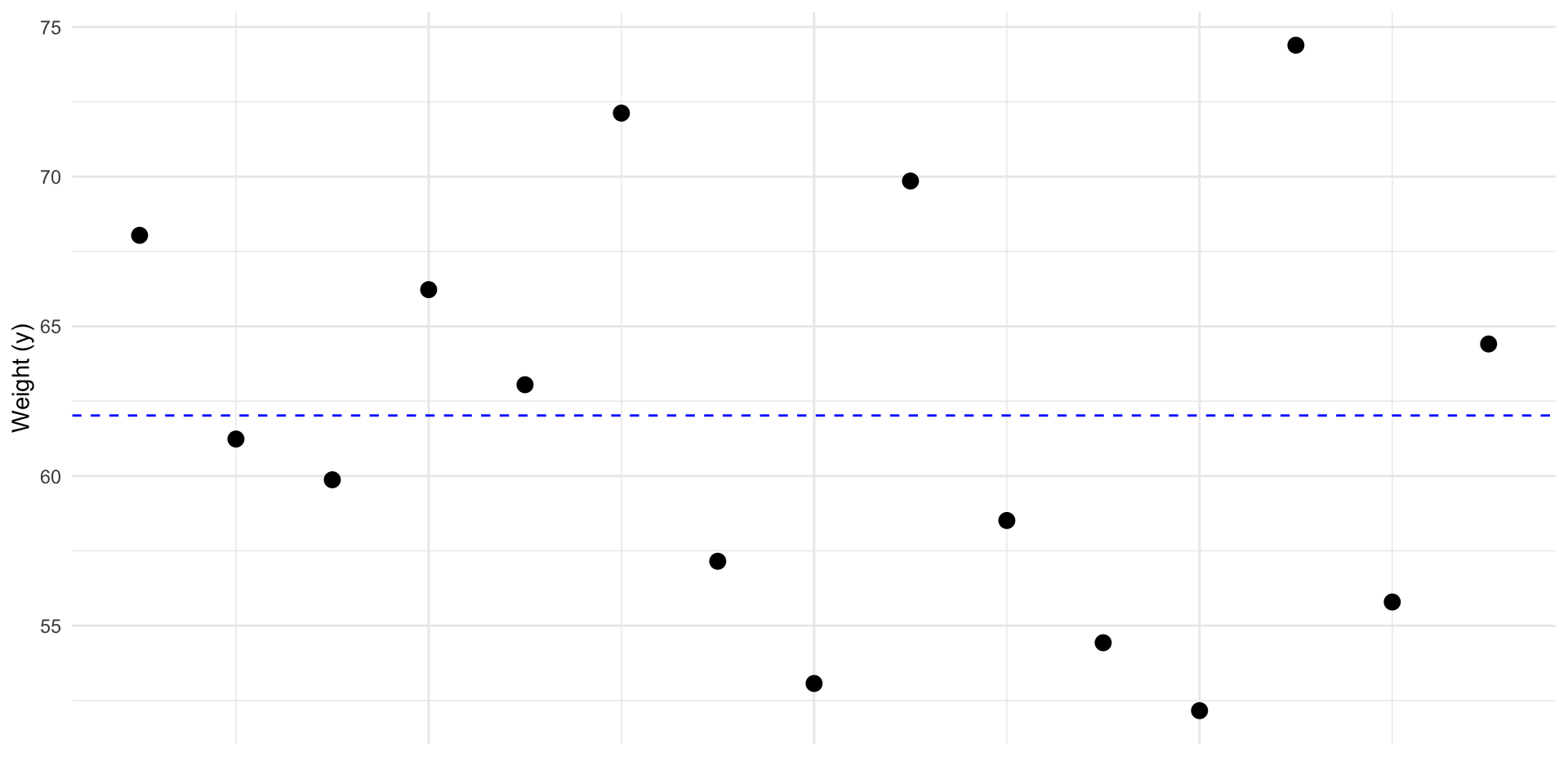
Predict y
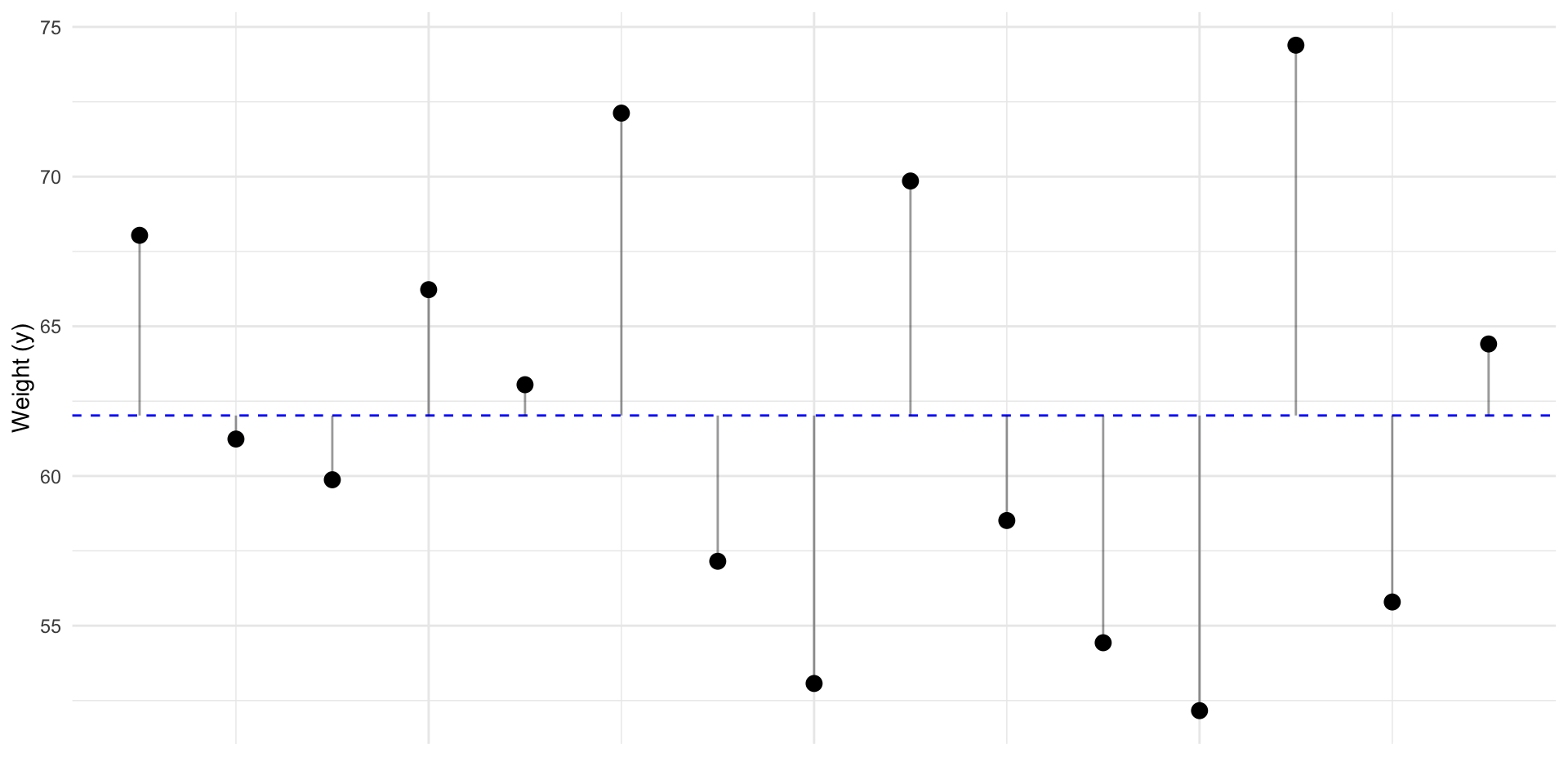
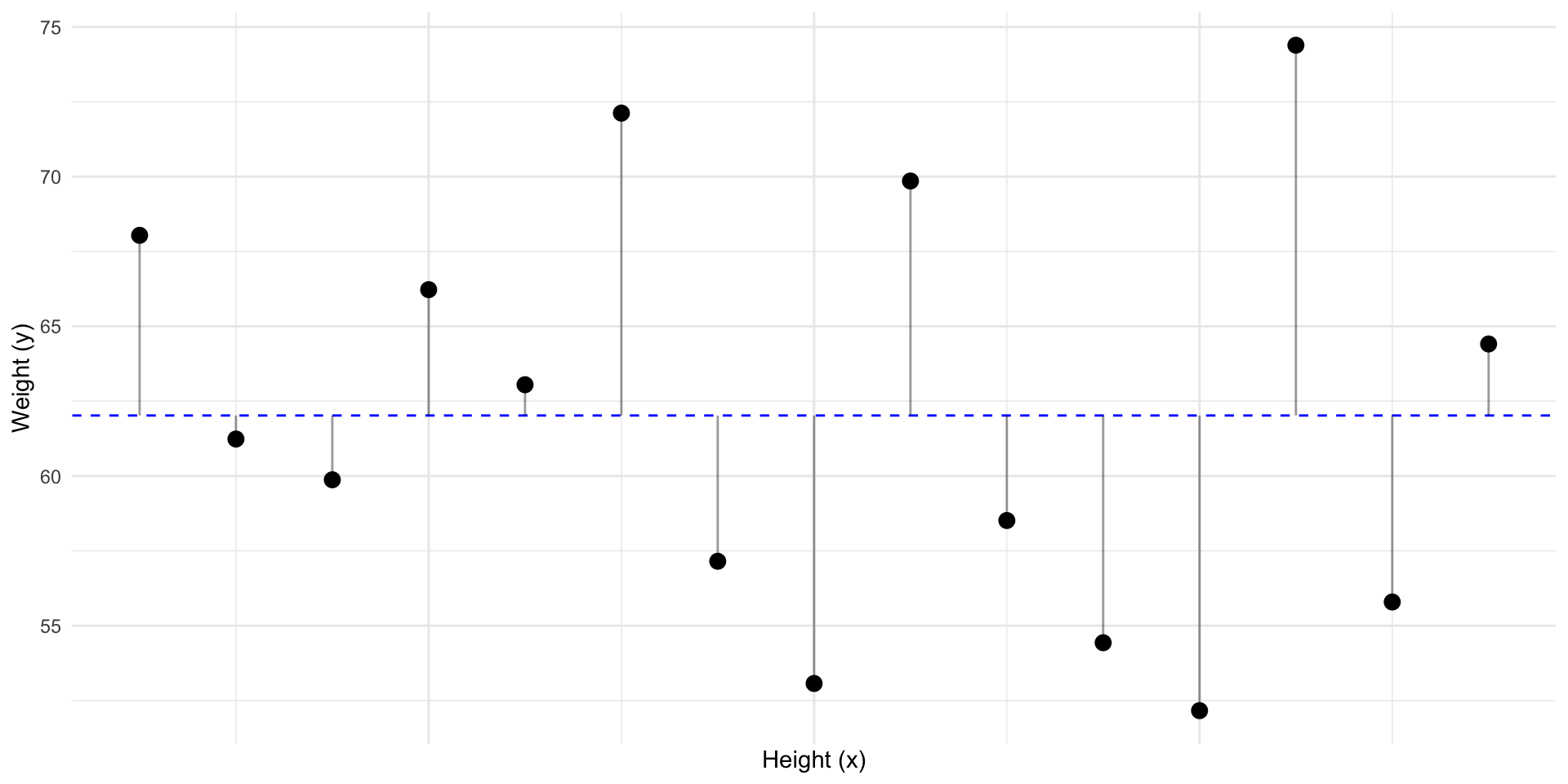
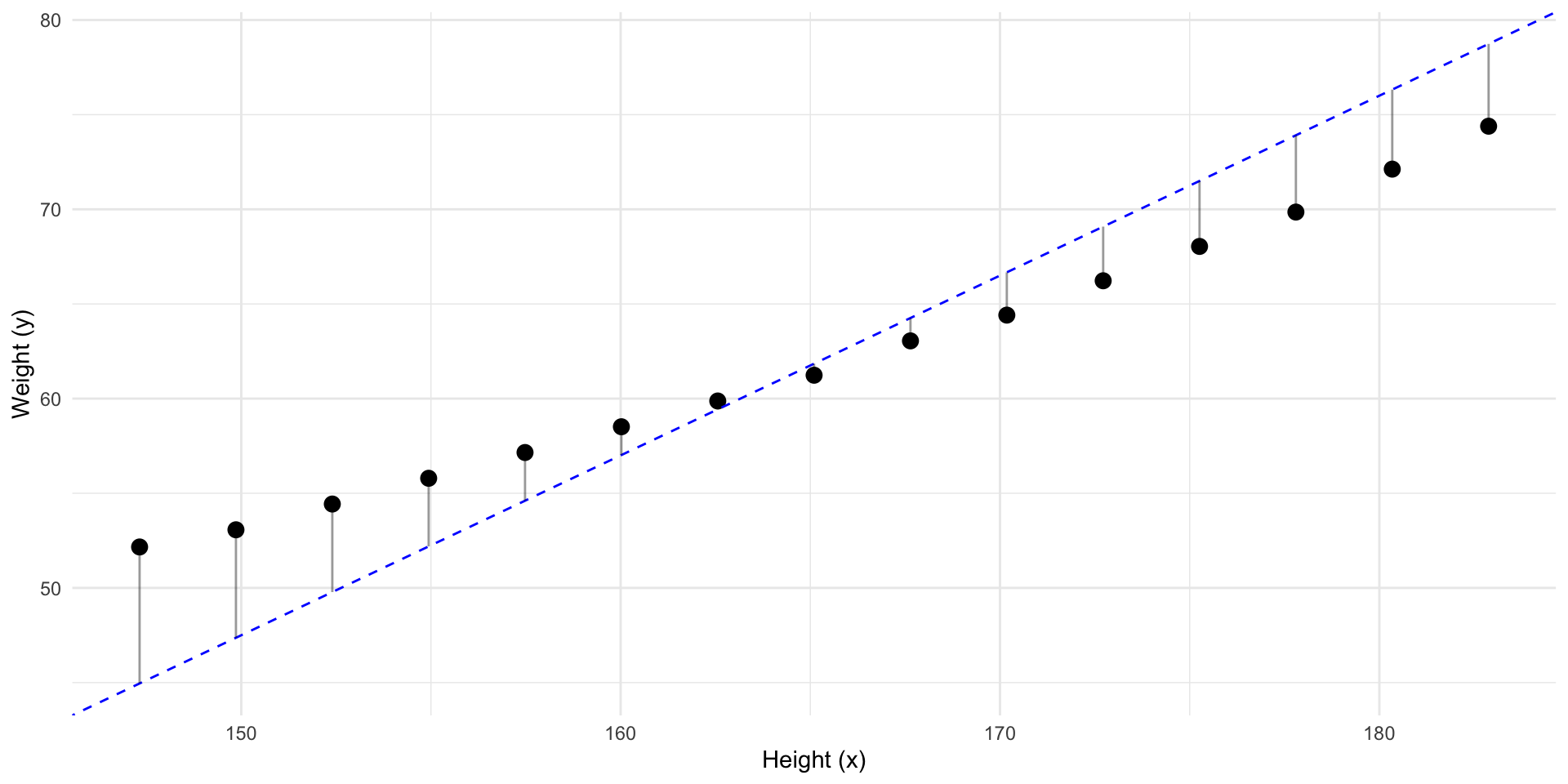
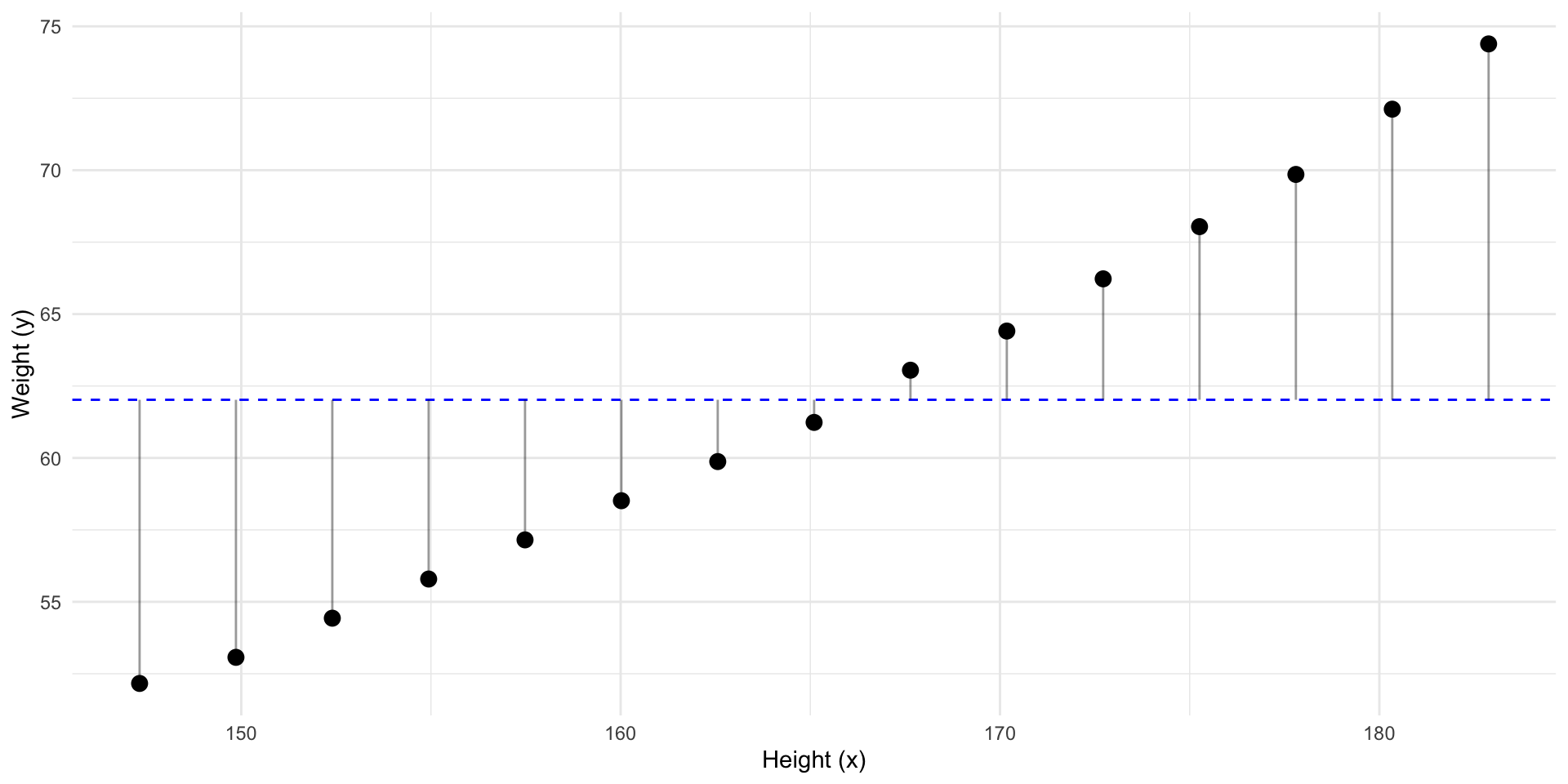
The best prediction for a new \(y\), is the mean: \(\bar y\). In other words \(\widehat y = \bar y\)
![]()
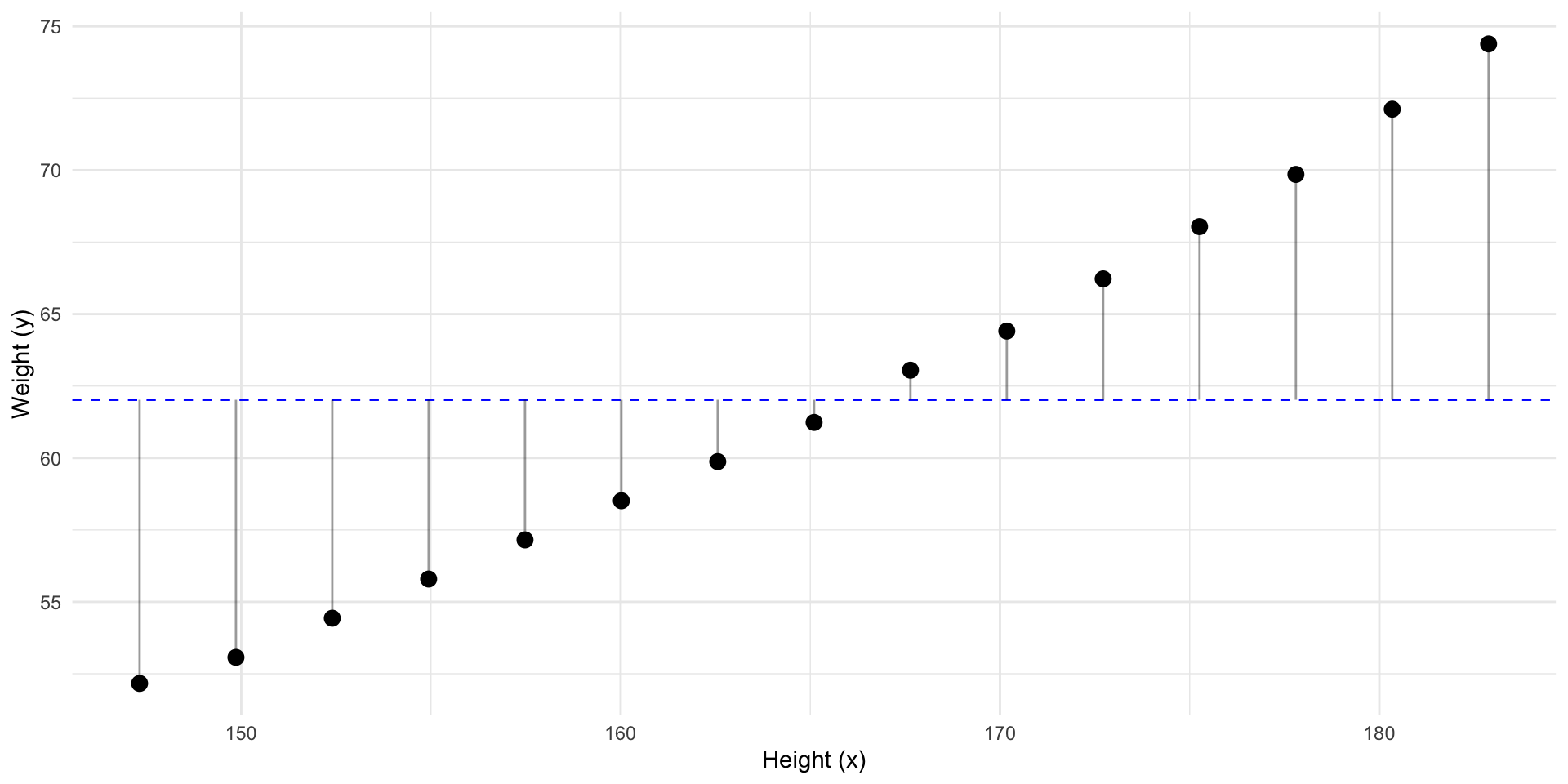
Predict y
So how “wrong” would we be if we had predicted \(\bar y\) for every \(y_i\)?
![]()
Predict y
These “errors” are called residuals (\(residual_i = y_i - \widehat{y}_i\))
![]()
Predict y
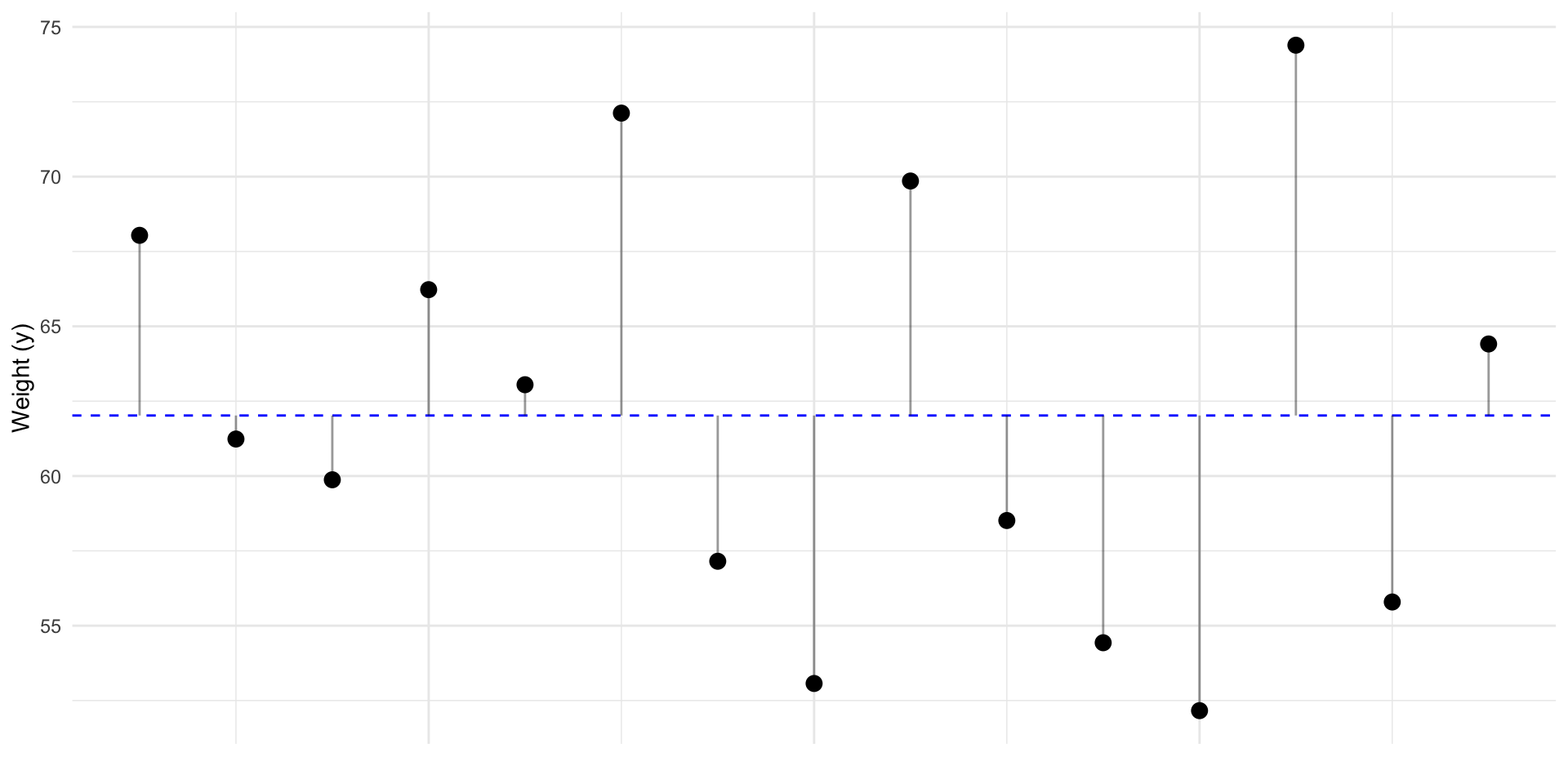
Given no other information, guessing \(\bar y\) minimizes the residuals.
![]()
Predict y
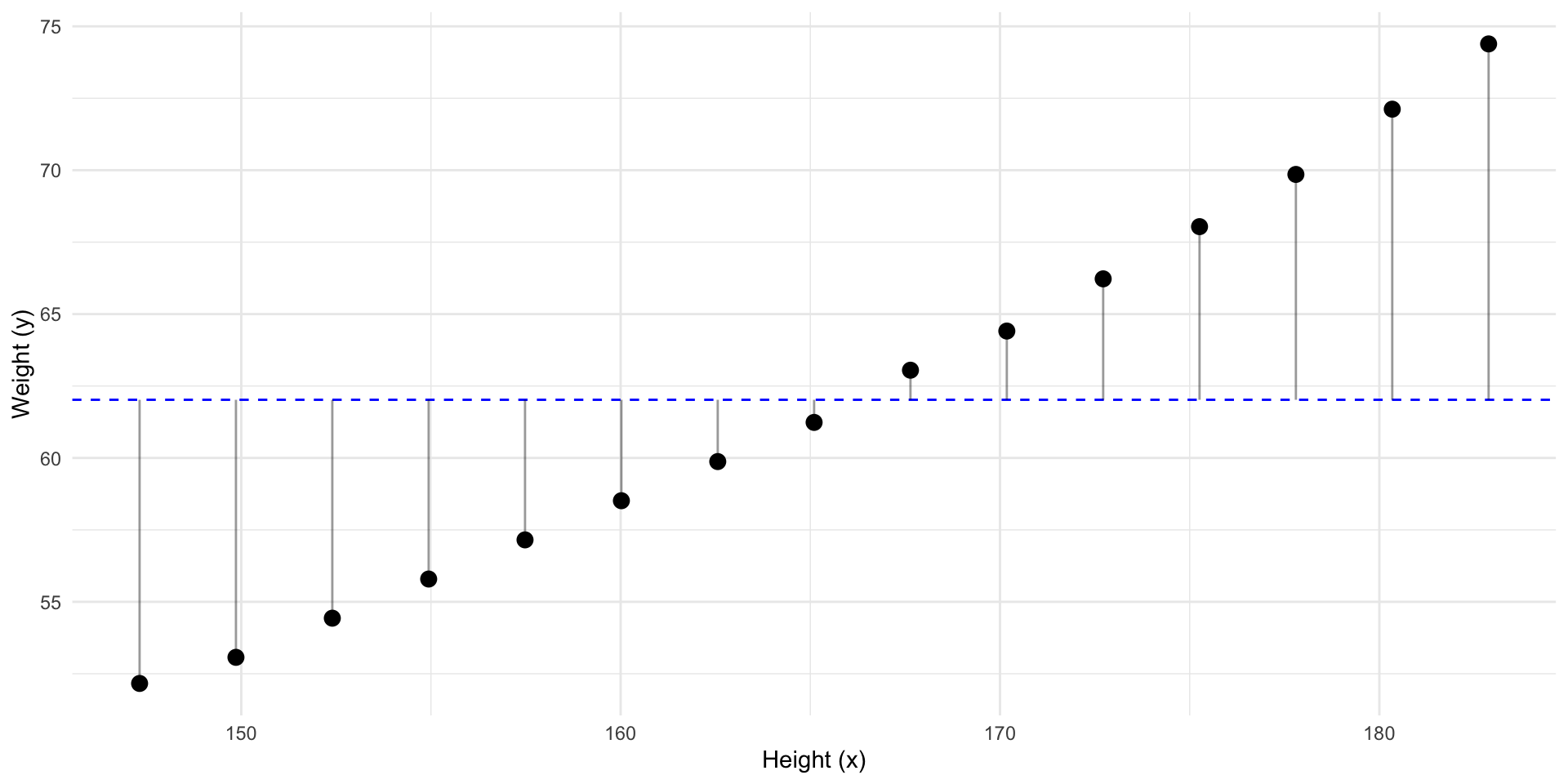
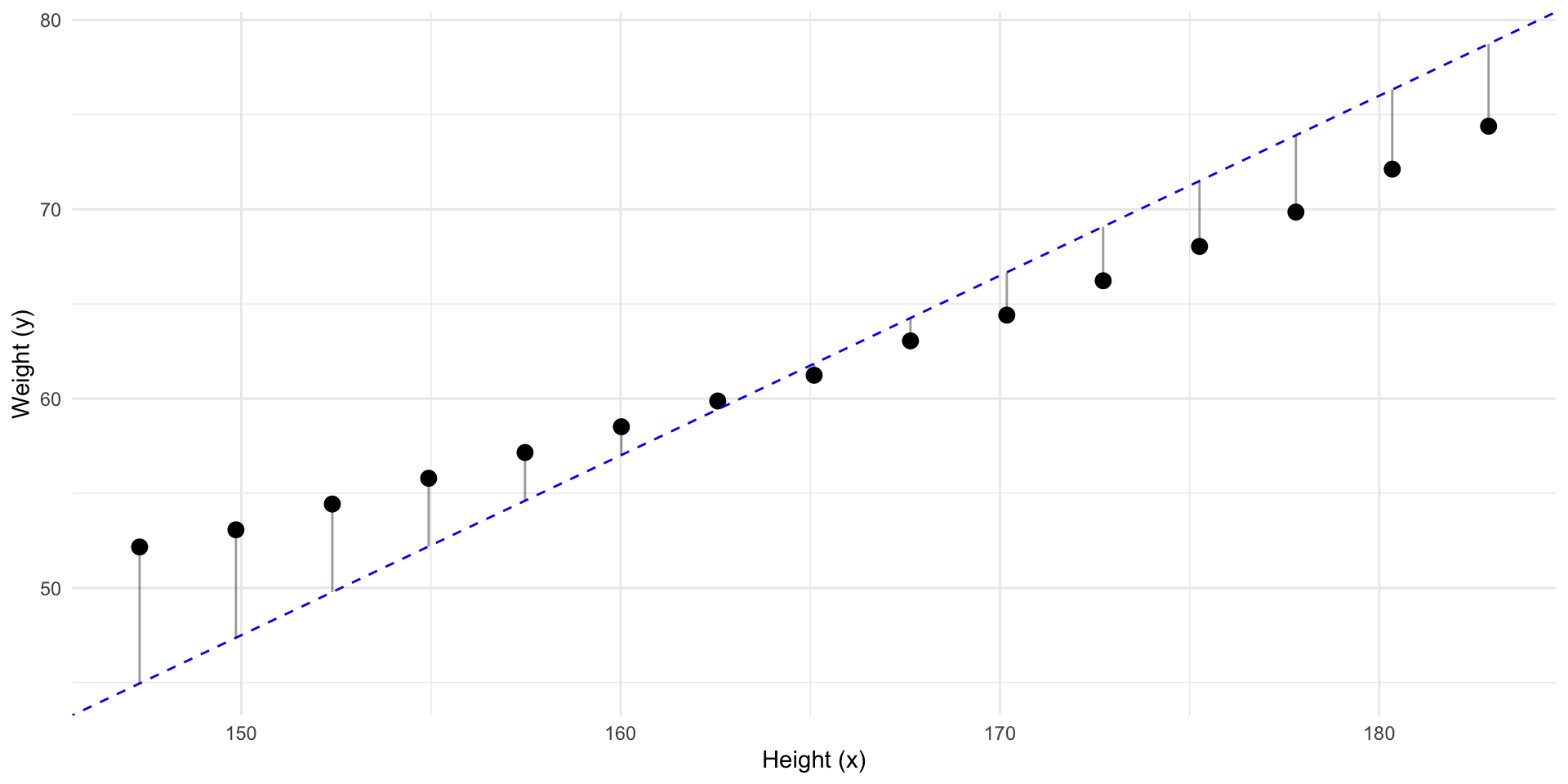
But, what if we have some other information?
![]()
Predict y
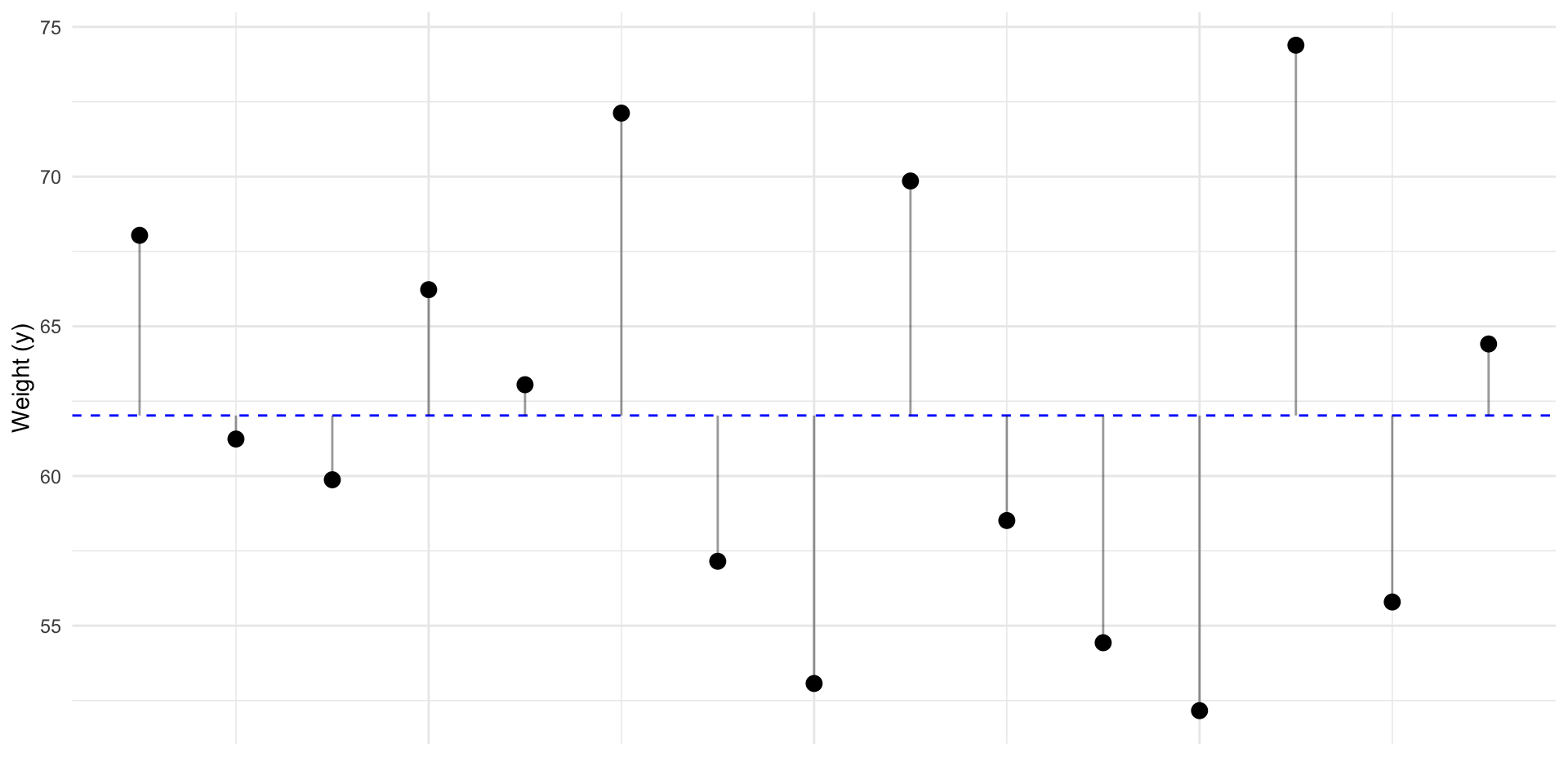
Can we make a better prediction of \(y\) using \(x\)?
![]()
Predict y
If we sort by that information…
![]()
Predict y
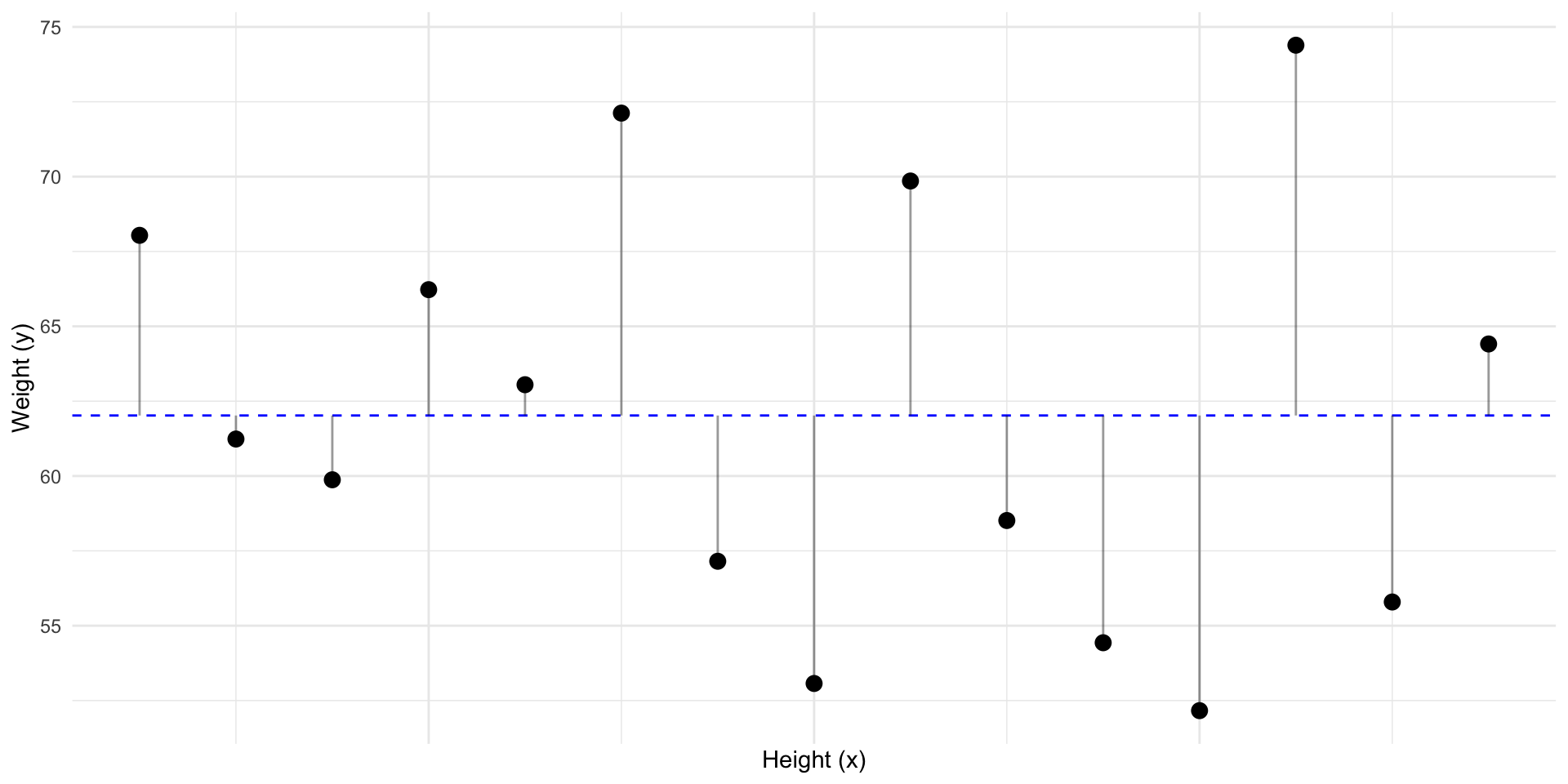
Can we improve our best guess of \(y\)?
![]()
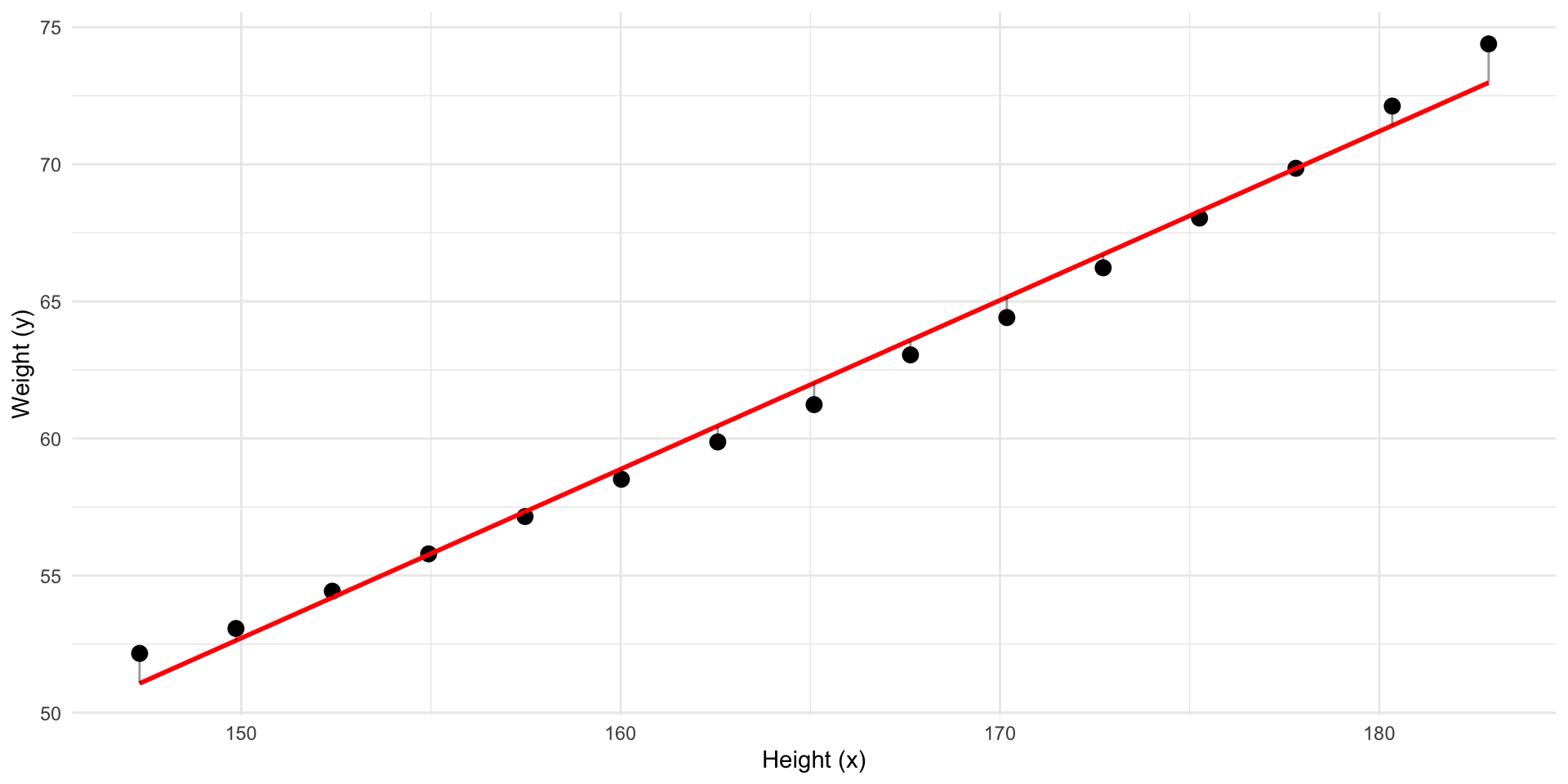
Predict y
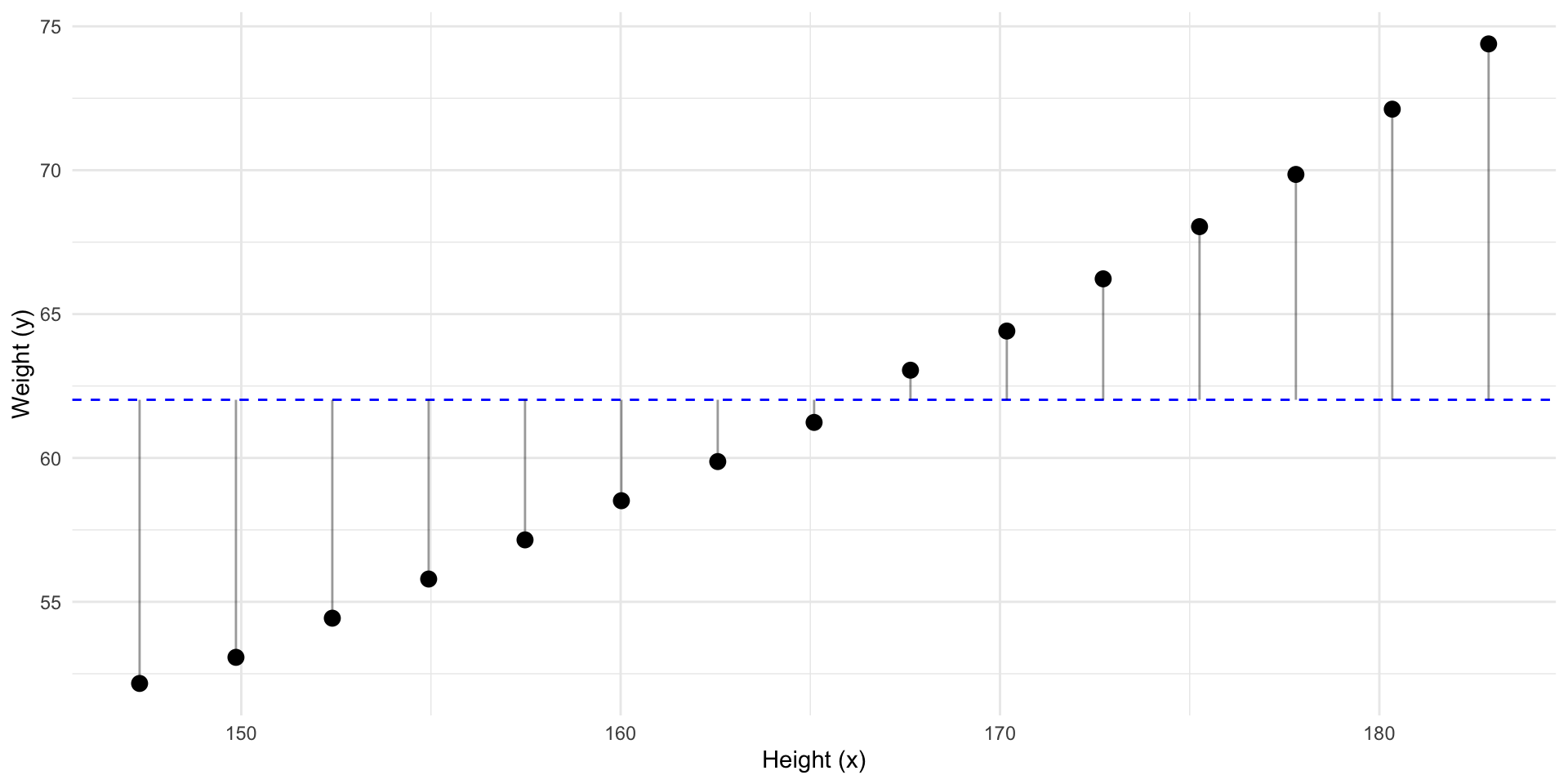
Can we draw a straight line with less residuals?
![]()
Predict y
Can we draw a line with less residuals?
![]()
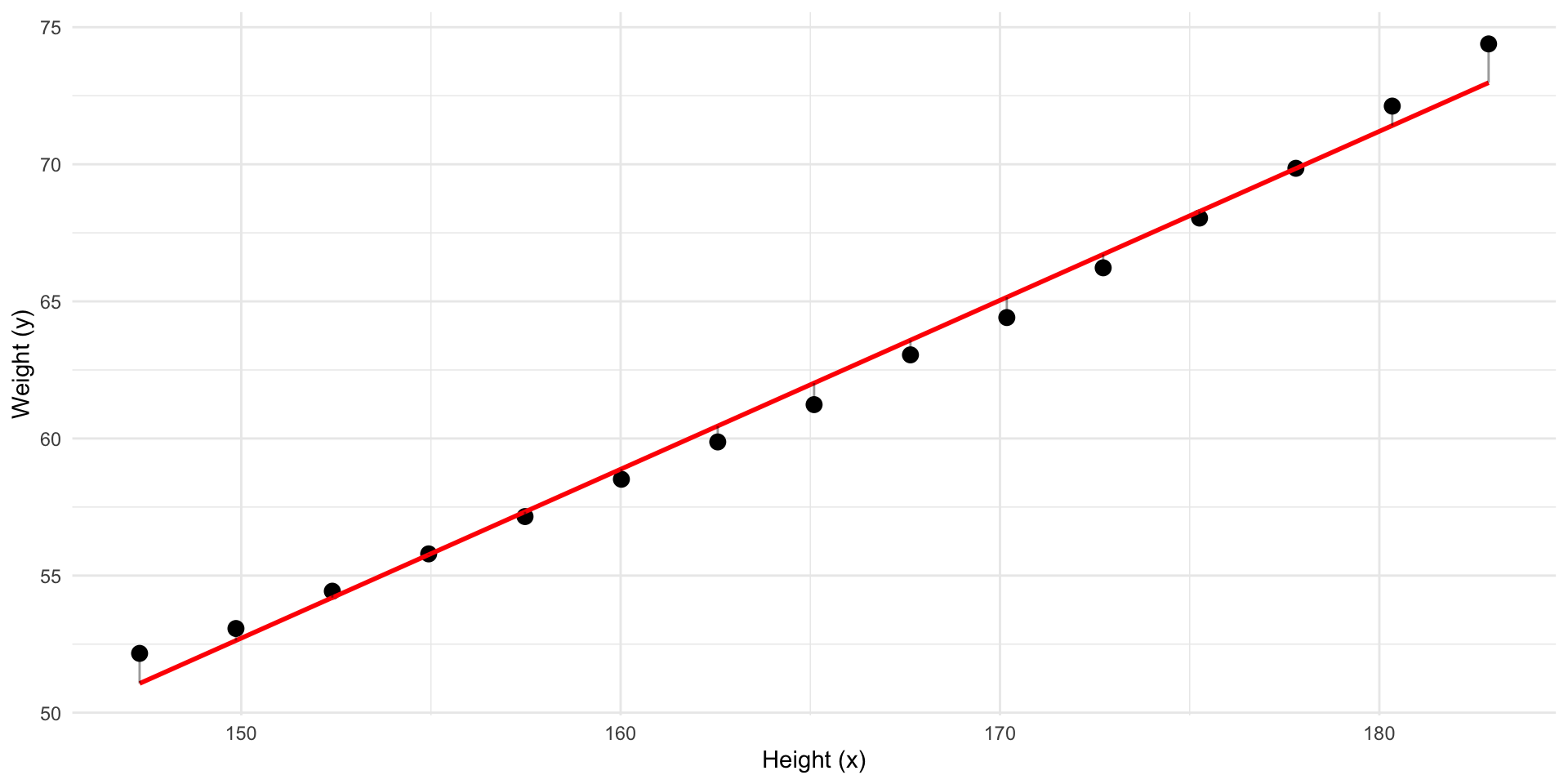
Predict y using x
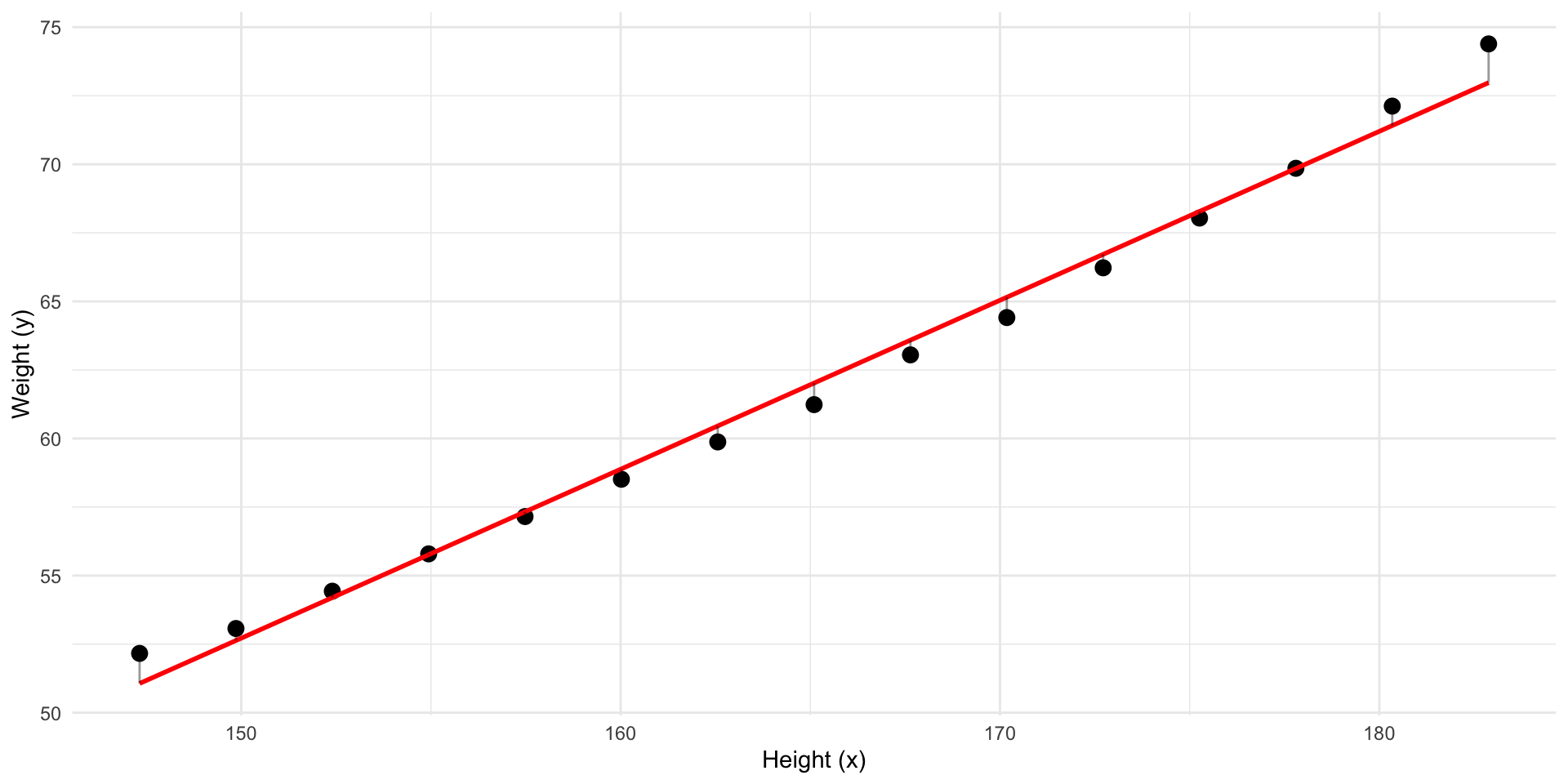
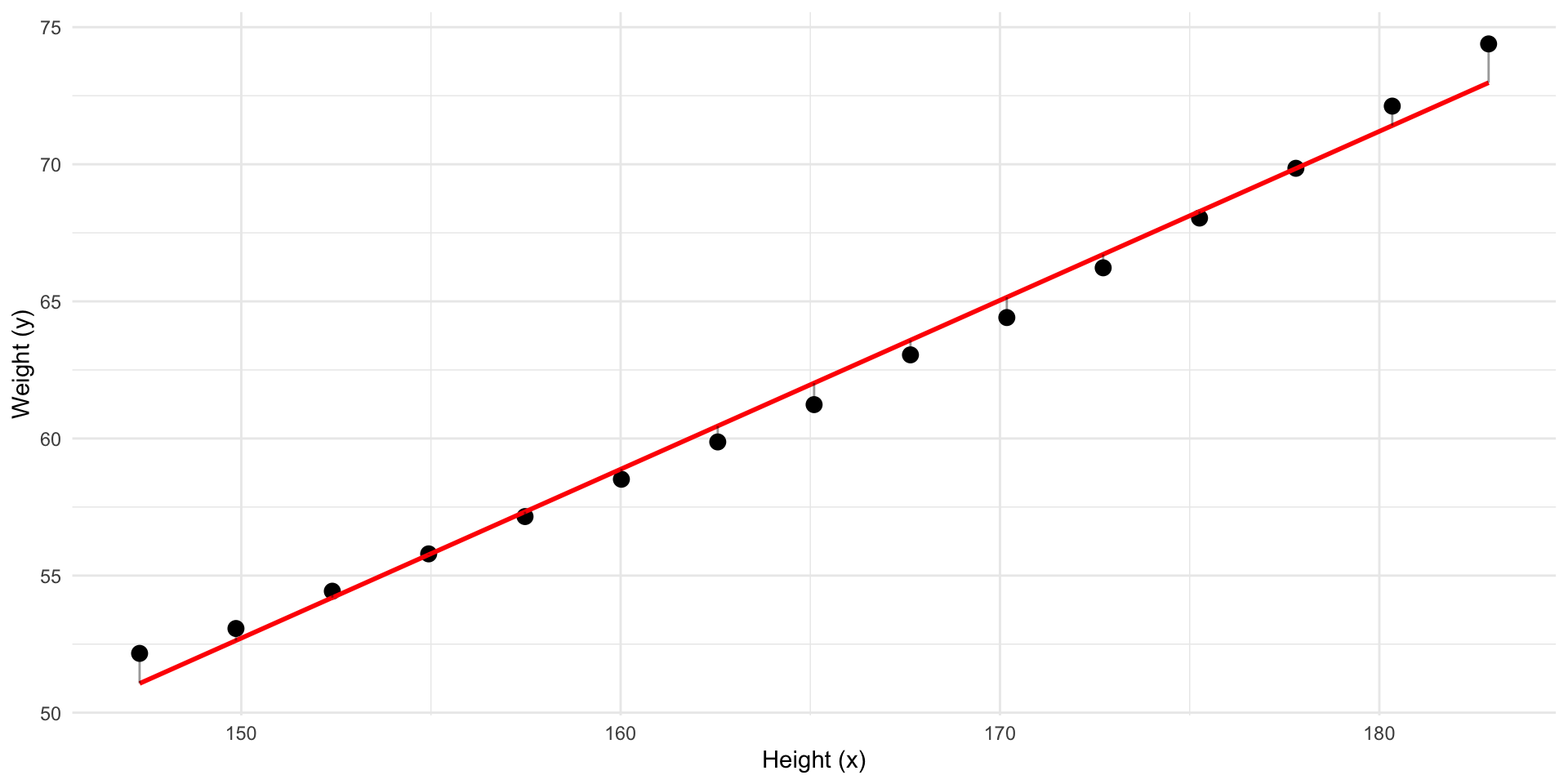
Better! But what line has the least residuals?
![]()
Predict y using x
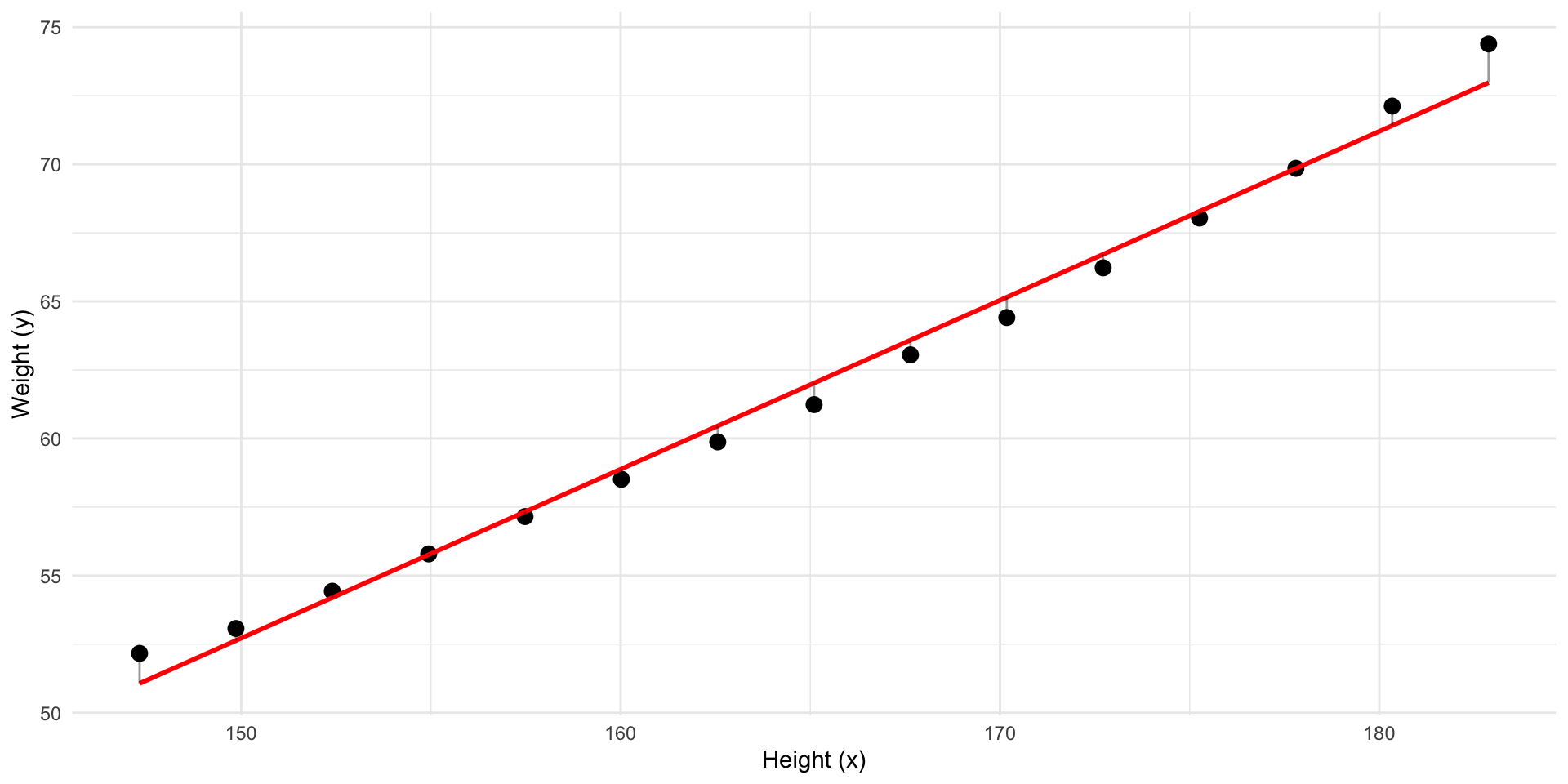
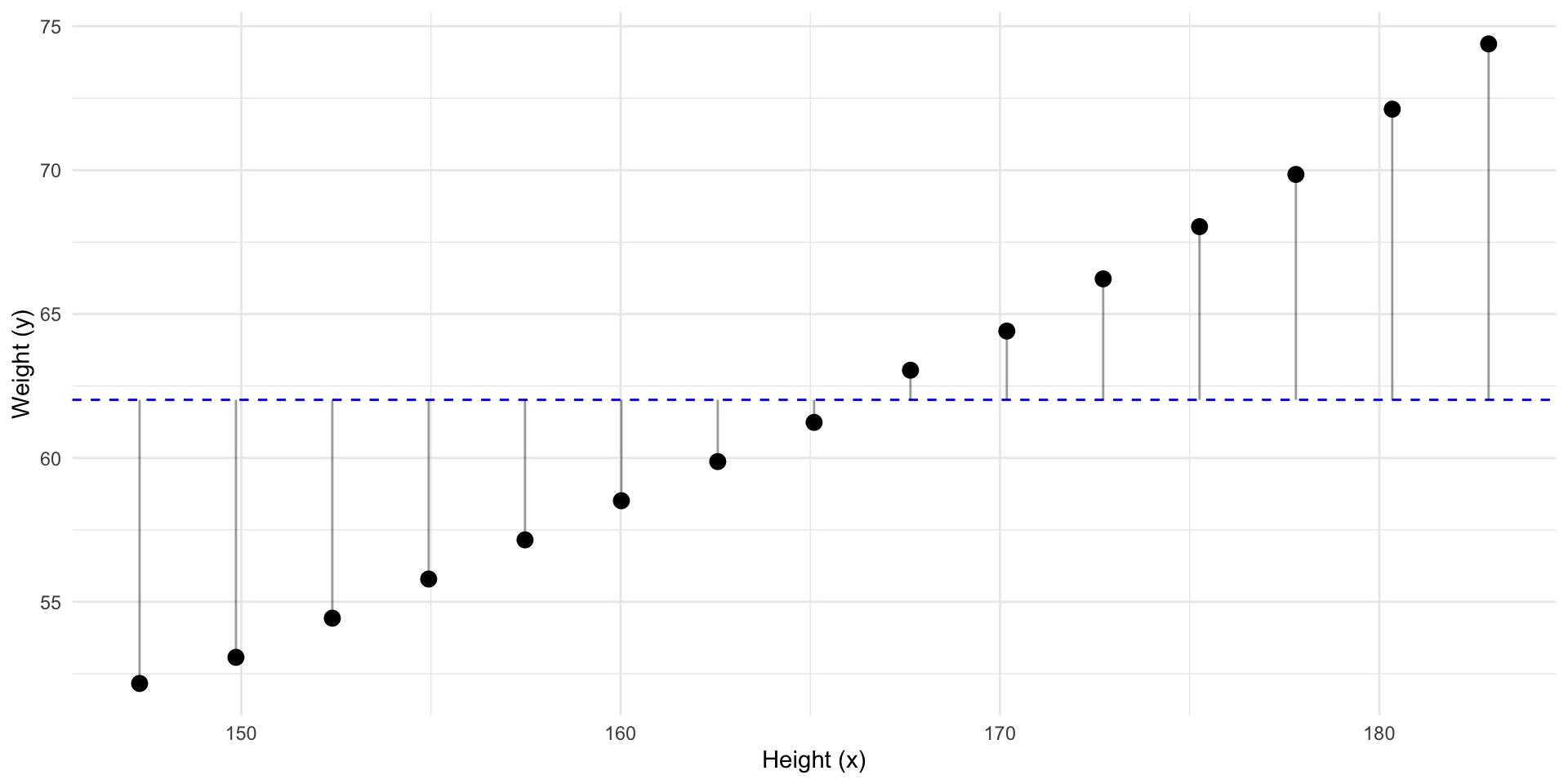
This line has the least residuals. It’s a regression line.
![]()
Predict y using x
We have fitted a model to our data.
- The model predict \(y\) using \(x\)
- This means that if we know a \(x\) we can calculate the model’s prediction of \(y\)
- It’s a representation of the association between the variables in our data.
- Currently it’s in the form of a straight line equation
The straight line equation
\[
y = a + b \cdot x
\] Where:
\(a\) is the intercept
\(b\) is the slope
A Simple Example
\[
y = 0 + 1 \cdot x
\]
- If \(x = 2\), then \(y =\)?
- \(2\)
- If \(x = 10\), then \(y =\)?
- \(10\)
Another
\[
y = 21 + 2 \cdot x
\]
- If \(x = 0\), then \(y =\)?
- \(21\)
- If \(x = 10\), then \(y =\)?
- \(41\)
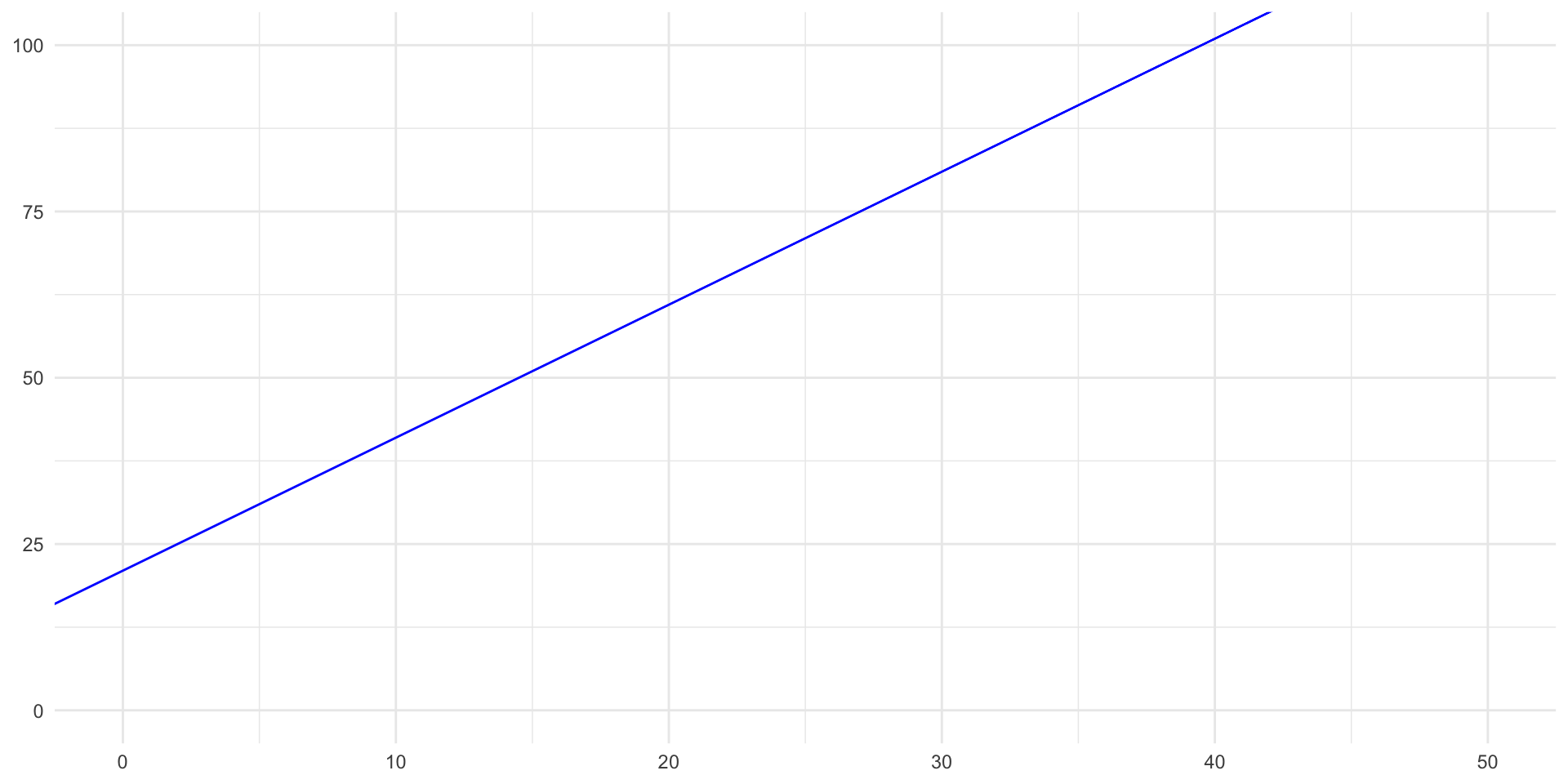
Our Model Equation
\[
\widehat{y} = -39.7 + 0.62 \cdot x
\]
- If \(x = 160\), then \(y = ?\)
- If height increases by 1 cm, how much would predicted weight increases by?
- \(0.62kg\)
- The slope tells us how \(y\) changes when \(x\) increases by one unit.
- What would be the predicted weight of someone with \(0\) height?
Our Model Equation
Call:
lm(formula = weight ~ height, data = women)
Residuals:
Min 1Q Median 3Q Max
-0.7862 -0.5141 -0.1739 0.3364 1.4137
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -39.69694 2.69296 -14.74 1.71e-09 ***
height 0.61610 0.01628 37.85 1.09e-14 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.6917 on 13 degrees of freedom
Multiple R-squared: 0.991, Adjusted R-squared: 0.9903
F-statistic: 1433 on 1 and 13 DF, p-value: 1.091e-14
Let’s stop and summarise
With a regression, we can describe a pattern between variables in our data — like height and weight — using a mathematical model, like a straight line.
- We have quantified an association.
- This might represent some “real” association in the “real” world.
What is our assumed model?
But the real-world is messy:
- Two people with the same height might weigh different amounts.
- There are many factors we don’t measure or can’t explain.
- Our data might be off.
- It is why we get residuals
We can write this as an assumed model:
\[
Y_i = \beta_0 + \beta_1 X_i + \varepsilon_i
\]
Understanding the model
\[
Y_i = \beta_0 + \beta_1 X_i + \varepsilon_i
\]
- \(Y_i\) and \(X_i\) are random variables (population level)
- \(\beta_0 + \beta_1 X_i\): the systematic part — recognize the straight line?
- \(\varepsilon_i\): the unsystematic part — the error.
From Model to Prediction
From our sample, we estimate:
\[
\widehat{y}_i = \hat{\beta}_0 + \hat{\beta}_1 x_i
\]
- \(x_i\): observed weight for individual \(i\)
- \(\widehat{y}_i\): our predicted height for individual \(i\)
- \(\hat{\beta}_0\): estimated intercept. \(\hat{\beta}_1\): estimated slope.
- \(r_i = y_i - \widehat{y}_i\): the residual — how far off our prediction was
To summarize
Observed Data: \((x_i, y_i)\) — what we actually see
Assumed Model: \(Y_i = \beta_0 + \beta_1 X_i + \varepsilon_i\)
- includes error \(\varepsilon_i\) (unknown, unobserved)
Fitted Model: \(\widehat{y}_i = \hat{\beta}_0 + \hat{\beta}_1 x_i\)
- produces residuals \(r_i = y_i - \widehat{y}_i\) (known, measurable)
- The assumed model is a hypothesis about how \(Y\) might relate to \(X\)
- The fitted model describes the data and “fits” the model
- Residuals ≠ Errors — but both reflect imperfect predictions