ego_id age unemployed mode
1 1 33 0 walk
2 2 59 0 car
3 3 39 0 walk
4 4 64 0 walk
5 5 67 0 walk
6 6 20 0 walk
7 7 45 0 car
8 8 64 0 car
9 9 47 1 walk
10 10 42 0 walk
11 11 68 0 car
12 12 42 0 walk
13 13 53 1 walk
14 14 48 0 walk
15 15 23 1 walk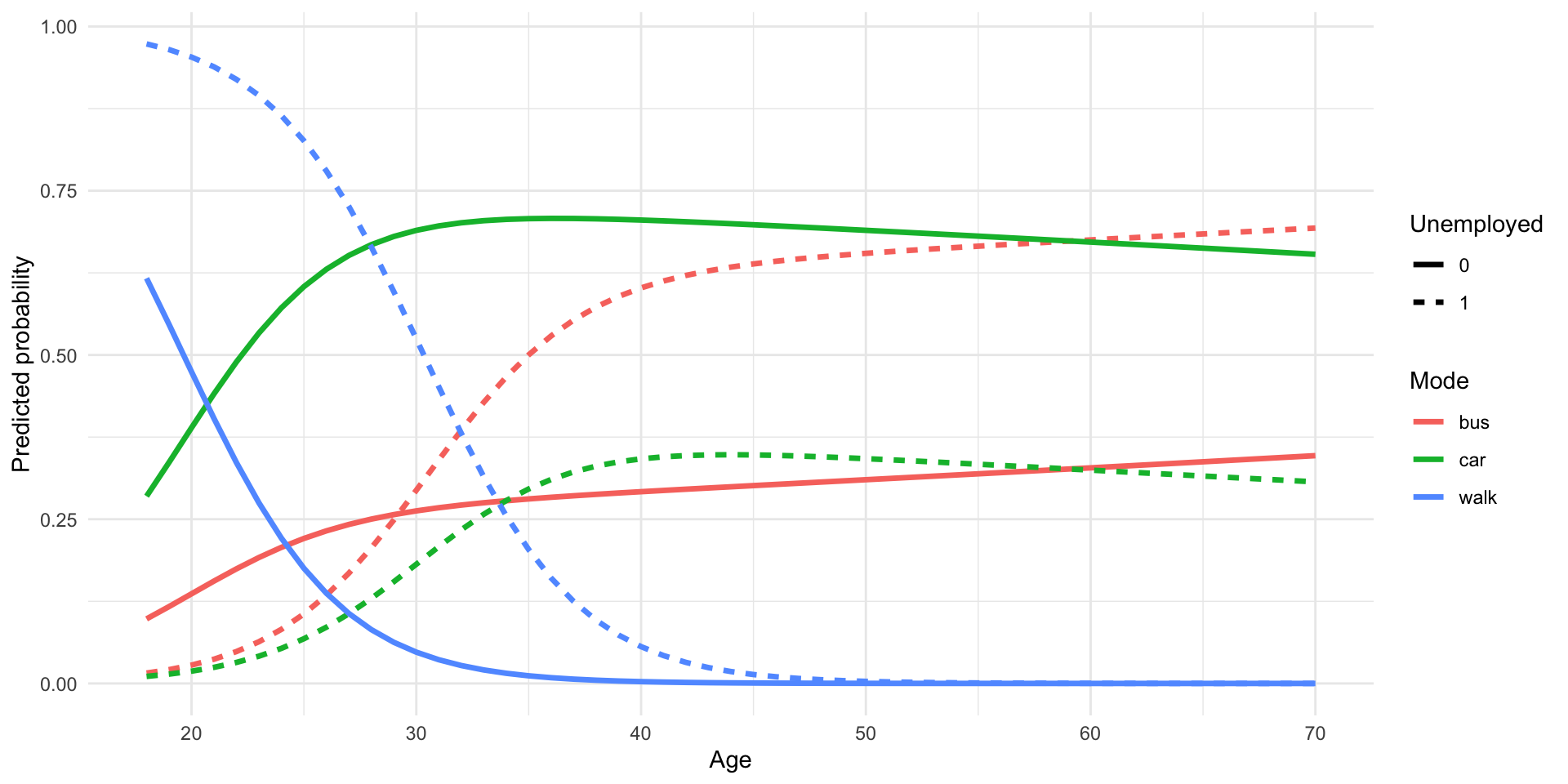
Main assumption: Independence of Irrelevant Alternatives (IIA) ☢️
IIA says the relative odds of choosing A over B does not depend on any other option C.
Any other choice option is irrelevant for A and B.
Adding or removing other options does not change \(\frac{P(A)}{P(B)}\)
Assumes options have no unobserved similarity


Social distance & boundaries ⟷
We see the same divides later in life:
This is the logic of ingroup vs. outgroup (Allport 1954).
We can call this social boundaries or social distance.